25/01/2023 • Jon Carrick
Understanding the ever-changing market with deep-learning techniques
CRO & UX Article

As an online business, it is fundamental to have an understanding of where you stand in the digital market. In a lot of cases, this may be defined simply by what your brand is offering compared to others. But how do we know for sure which other brands are direct competitors? And are there any undiscovered opportunities to work with others?
A recent paper published in the Journal of Marketing shows that deep learning can be leveraged to identify market structure through social media users’ interactions with brands. The authors’ work differs from previous studies as it considers brand-user engagement at the top of the purchase funnel without making any initial assumptions about market structure. Their findings are determined through the learning of connections between users and brands by artificial intelligence (AI).
A crash course in AI
In AI, a typical machine learning task could be something like classifying cats and dogs from images, where the predefined classes ‘cats’ and ‘dogs’ are what the algorithm is told to identify based on specific features defined by humans. Deep learning is a branch of AI that finds patterns in big datasets without being told explicitly what to look for, i.e. it learns its own interpretation of the data. For example, if trained on a dataset of cat and dog images, it may determine by itself that ‘fluffiness’, ‘nose-size’, or more complex features such as the ratio of tail length to body size are the best distinguishers. However, there will likely also be completely ambiguous features that do not possess any obvious interpretation, yet represent underlying patterns within the data.
This is where deep learning shines; it is a data-driven approach to understanding complex data structures without enforcing our own preconceptions or biases. But how exactly can this be used in the context of market structure and how does it work?
The data: social media interactions
The objective of the study is to determine how similar different brands are in order to identify potential opportunities for businesses in the digital market, as well as competitors. The dataset used in this study comprises more than 5000 of the top brands on Facebook (determined by the number of followers of their pages), covering 25 categories (e.g. auto, finance, fashion etc.) and engagement is defined by likes and comments from 25 million users. This puts the task firmly in the scope of ‘Big Data’; it would be impractical to manually process the dataset and instead requires advanced AI methods to analyse.
To understand market structure when there are many millions of interactions, the trick is to create a (relatively) low-dimensional representation of each brand - in this case, 300 dimensions. This turns complex data structures into vectors (essentially a list of numbers) which can be quantifiably compared. The input to the neural network in this task is a complex map of brand-user interactions. Through training, the network model can be used to input a brand’s user engagement data and determine its corresponding low-dimensional representation.
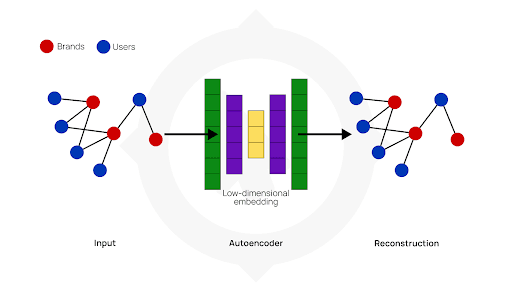
How to train the deep neural network
Neural networks come in many different types, with architectures suited for different tasks. Dimensionality reduction can be accomplished by training an autoencoder network model. Autoencoders compress the data at an information bottleneck, before attempting to reconstruct the original data input. Reconstruction is necessary as it enforces the network to retain only what it considers useful information.
The network is trained by incorporating a loss function, in which the output and input are compared and the discrepancy is calculated. The network updates each connection in order to minimise the loss function. Through many iterations, the optimal model is developed as it learns which connections enable the necessary flow of information while identifying data patterns and rejecting random fluctuations.
Main findings
Once the model has been developed, brands can be compared by their 300-dimension vectors. We cannot visualise 300 dimensions, but through a data technique known as t-SNE (t-distributed stochastic neighbour embedding) the brand vectors are projected onto a 2D graph. The meaning of the 2 dimensions is completely arbitrary, but provides a visual comparison between brands where the closer together brands appear on the graph, the more similar they are. This is determined by overlapping user engagements that are identified by the trained model. This provides a good visualisation of brand groupings, where clusters have emerged from the data.
To quantify similarities, the authors employ a cosine similarity, which takes into account the angle between the different brand vectors. A small angle between two vectors indicates that these brands are similar and share the same region in the market structure.

This tool means that, for any given brand, the cosine similarity of all other brands can be used to determine which brands occupy the same market space. Not only can the biggest Facebook brands be compared, but when including smaller brands (specifically travel brands with as few as ~1000 followers) they cluster together. This shows that the network has captured an understanding of market structure that can be applied across a very wide range of brand followings.
Additionally, one of the main benefits of this process is that the data can be collected relatively quickly, meaning that analysis can be carried out at different points in time, effectively tracking changes in the market. The authors demonstrate that there is a clear shift in market structure following significant events, including Amazon’s purchase of Whole Foods, and Tesla announcing its Model 3.
To summarise
It is encouraging to see progress in digital marketing research that incorporates advanced AI technologies. With deep learning of brand-user engagement on Facebook, a data-driven representation of market structure can be determined and, with a method to track changes across time, there is potential for even smaller digital businesses to be able to track their position in an ever-changing market.
Share it with friends



SIGN UP FOR OUR NEWSLETTER
Once a month, every month
A monthly round up of our expert insights, tips and careers - straight to your inbox.
43 Clicks North will use this information to be in touch and to provide updates and marketing. Please see our privacy policy.